dsxwjhf
- жµПиІИ: 70758 жђ°
- жАІеИЂ:

- жЭ•иЗ™: еЃЙеЊљ
-

жЦЗзЂ†еИЖз±ї
з§ЊеМЇзЙИеЭЧ
- жИСзЪДиµДиЃѓ ( 0)
- жИСзЪДиЃЇеЭЫ ( 0)
- жИСзЪДйЧЃз≠Ф ( 0)
е≠Шж°£еИЖз±ї
- 2016-05 ( 6)
- 2016-04 ( 18)
- 2015-09 ( 2)
- жЫіе§Ъе≠Шж°£...
жЬАжЦ∞иѓДиЃЇ
-
shaojie92пЉЪ
жШѓжѓПдЄАжђ°newзЪДжЧґеАЩйГљдЉЪжЙІи°МеИ§жЦ≠жШѓеР¶еРСRememberSetеҐЮ ...
JVM дєЛ OopMap еТМ RememberedSet -
biyeleiпЉЪ
...
JVM жЦ∞зФЯдї£дЄЇдљХйЬАи¶БдЄ§дЄ™ Survivor з©ЇйЧіпЉЯ -
173806613пЉЪ
Epollж®°еЮЛиѓ¶иІ£¬† http://t.cn/RaWYhJE
гАРиљђгАСжИСиѓїињЗжЬАе•љзЪД Epoll ж®°еЮЛиЃ≤иІ£ -
姩еЬ®жСФдЄ™пЉЪ
иѓЈжХЩдЄЛ OopMapжШѓжѓПдЄ™зЇњз®ЛйГљжЬЙдЄАдїљеРЧ ињШжШѓиѓіжХідЄ™жЦ∞зФЯдї£жЬЙдЄА ...
JVM дєЛ OopMap еТМ RememberedSet -
tianqiaaqqпЉЪ
    
гАРиљђгАСRedis йЫЖзЊ§дєЛиЈѓзФ±
еОЯжЦЗеЬ∞еЭАпЉЪhttp://gnucto.blog.51cto.com/3391516/998509
дЉ†зїЯ MySQL + Memcached жЮґжЮДйБЗеИ∞зЪДйЧЃйҐШ
еЃЮйЩЕдЄК MySQL жШѓйАВеРИињЫи°МжµЈйЗПжХ∞жНЃе≠ШеВ®зЪДпЉМйАЪињЗ Memcached е∞ЖзГ≠зВєжХ∞жНЃеК†иљљеИ∞ cache пЉМеК†йАЯиЃњйЧЃпЉМеЊИе§ЪеЕђеПЄйГљжЫЊзїПдљњзФ®ињЗињЩж†ЈзЪДжЮґжЮДпЉМдљЖйЪПзЭАдЄЪеК°жХ∞жНЃйЗПзЪДдЄНжЦ≠еҐЮеК†пЉМеТМиЃњйЧЃйЗПзЪДжМБзї≠еҐЮйХњпЉМжИСдїђйБЗеИ∞дЇЖеЊИе§ЪйЧЃйҐШпЉЪ
1. MySQL йЬАи¶БдЄНжЦ≠ињЫи°МжЛЖеЇУжЛЖи°®пЉМ Memcached дєЯйЬАдЄНжЦ≠иЈЯзЭАжЙ©еЃєпЉМжЙ©еЃєеТМзїіжК§еЈ•дљЬеН†жНЃдЇЖе§ІйЗПеЉАеПСжЧґйЧігАВ
2. Memcached дЄО MySQL жХ∞жНЃеЇУжХ∞жНЃдЄАиЗіжАІйЧЃйҐШгАВ
3. Memcached жХ∞жНЃеСљдЄ≠зОЗдљОжИЦеЃХжЬЇпЉМе§ІйЗПиЃњйЧЃзЫіжО•з©њйАПеИ∞ DB пЉМ MySQL жЧ†ж≥ХжФѓжТСгАВ
4. иЈ®жЬЇжИњ cache еРМж≠•йЧЃйҐШгАВ
дЉЧе§Ъ NoSQL зЩЊиК±йљРжФЊпЉМе¶ВдљХйАЙжЛ©
жЬАињСеЗ†еєіпЉМдЄЪзХМдЄНжЦ≠жґМзО∞еЗЇеЊИе§ЪеРДзІНеРДж†ЈзЪД NoSQL дЇІеУБпЉМйВ£дєИе¶ВдљХжЙНиГљж≠£з°ЃеЬ∞дљњзФ®е•љињЩдЇЫдЇІеУБпЉМжЬАе§ІеМЦеЬ∞еПСжМ•еЕґйХње§ДпЉМжШѓжИСдїђйЬАи¶БжЈ±еЕ•з†Фз©ґеТМжАЭиАГзЪДйЧЃйҐШпЉМеЃЮйЩЕељТж†єзїУеЇХжЬАйЗНи¶БзЪДжШѓдЇЖиІ£ињЩдЇЫдЇІеУБзЪДеЃЪдљНпЉМеєґдЄФдЇЖиІ£еИ∞жѓПжђЊдЇІеУБзЪДдЉШзЉЇзВєпЉМеЬ®еЃЮйЩЕеЇФзФ®дЄ≠еБЪеИ∞жЙђйХњйБњзЯ≠пЉМжАїдљУдЄКињЩдЇЫ NoSQL дЄїи¶БзФ®дЇОиІ£еЖ≥дї•дЄЛеЗ†зІНйЧЃйҐШпЉЪ
1. е∞СйЗПжХ∞жНЃе≠ШеВ®пЉМйЂШйАЯиѓїеЖЩиЃњйЧЃгАВж≠§з±їдЇІеУБйАЪињЗжХ∞жНЃеЕ®йГ® in-memory зЪДжЦєеЉПжЭ•дњЭиѓБйЂШйАЯиЃњйЧЃпЉМеРМжЧґжПРдЊЫжХ∞жНЃиРљеЬ∞зЪДеКЯиГљпЉМеЃЮйЩЕдЄКињЩж≠£жШѓ Redis жЬАдЄїи¶БзЪДйАВзФ®еЬЇжЩѓгАВ
2. жµЈйЗПжХ∞жНЃе≠ШеВ®пЉМеИЖеЄГеЉПз≥їзїЯжФѓжМБпЉМжХ∞жНЃдЄАиЗіжАІдњЭиѓБпЉМжЦєдЊњзЪДйЫЖзЊ§иКВзВєжЈїеК†/еИ†йЩ§гАВињЩжЦєйЭҐжЬАеЕЈдї£и°®жАІзЪДжШѓ dynamo еТМ bigtable 2зѓЗиЃЇжЦЗжЙАйШРињ∞зЪДжАЭиЈѓгАВеЙНиАЕжШѓдЄАдЄ™еЃМеЕ®жЧ†дЄ≠ењГзЪДиЃЊиЃ°пЉМиКВзВєдєЛйЧійАЪињЗ gossip жЦєеЉПдЉ†йАТйЫЖзЊ§дњ°жБѓпЉМжХ∞жНЃдњЭиѓБжЬАзїИдЄАиЗіжАІпЉЫеРОиАЕжШѓдЄАдЄ™дЄ≠ењГеМЦзЪДжЦєж°ИиЃЊиЃ°пЉМйАЪињЗз±їдЉЉдЄАдЄ™еИЖеЄГеЉПйФБжЬНеК°жЭ•дњЭиѓБеЉЇдЄАиЗіжАІпЉМжХ∞жНЃеЖЩеЕ•еЕИеЖЩеЖЕе≠ШеТМ redo log пЉМзДґеРОеЃЪжЬЯ compat ељТеєґеИ∞з£БзЫШдЄКпЉМе∞ЖйЪПжЬЇеЖЩдЉШеМЦдЄЇй°ЇеЇПеЖЩпЉМжПРйЂШеЖЩеЕ•жАІиГљгАВ
3. Schema free пЉМ auto-sharding з≠ЙгАВжѓФе¶ВзЫЃеЙНеЄЄиІБзЪДдЄАдЇЫжЦЗж°£жХ∞жНЃеЇУйГљжШѓжФѓжМБ schema-free зЪДпЉМзЫіжО•е≠ШеВ® json ж†ЉеЉПзЪДжХ∞жНЃпЉМеєґдЄФжФѓжМБ auto-sharding з≠ЙеКЯиГљпЉМжѓФе¶В mongodb гАВ
йЭҐеѓєињЩдЇЫдЄНеРМз±їеЮЛзЪД NoSQL дЇІеУБ,жИСдїђйЬАи¶Бж†єжНЃжИСдїђзЪДдЄЪеК°еЬЇжЩѓйАЙжЛ©жЬАеРИйАВзЪДдЇІеУБгАВ
Redis йАВзФ®еЬЇжЩѓпЉМе¶ВдљХж≠£з°ЃзЪДдљњзФ®
еЙНйЭҐеЈ≤зїПеИЖжЮРињЗпЉМ Redis жЬАйАВеРИжЙАжЬЙжХ∞жНЃ in-memory зЪДеЬЇжЩѓпЉМиЩљзДґ Redis дєЯжПРдЊЫжМБдєЕеМЦеКЯиГљпЉМдљЖеЃЮйЩЕжЫіе§ЪзЪДжШѓдЄАдЄ™ disk-backed зЪДеКЯиГљпЉМиЈЯдЉ†зїЯжДПдєЙдЄКзЪДжМБдєЕеМЦжЬЙжѓФиЊГе§ІзЪДеЈЃеИЂпЉМйВ£дєИеПѓиГље§ІеЃґе∞±дЉЪжЬЙзЦСйЧЃпЉМдЉЉдєО Redis жЫіеГПдЄАдЄ™еК†еЉЇзЙИзЪД Memcached пЉМйВ£дєИдљХжЧґдљњзФ® Memcached пЉМдљХжЧґдљњзФ® Redis еСҐ?
е¶ВжЮЬзЃАеНХеЬ∞жѓФиЊГ Redis дЄО Memcached зЪДеМЇеИЂпЉМе§Іе§ЪжХ∞йГљдЉЪеЊЧеИ∞дї•дЄЛиІВзВєпЉЪ
1. Redis дЄНдїЕдїЕжФѓжМБзЃАеНХзЪД k/v з±їеЮЛзЪДжХ∞жНЃпЉМеРМжЧґињШжПРдЊЫ list пЉМ set пЉМ sorted set пЉМ hash з≠ЙжХ∞жНЃзїУжЮДзЪДе≠ШеВ®гАВ
2. Redis жФѓжМБжХ∞жНЃзЪДе§ЗдїљпЉМеН≥ master-slave ж®°еЉПзЪДжХ∞жНЃе§ЗдїљгАВ
3. Redis жФѓжМБжХ∞жНЃзЪДжМБдєЕеМЦпЉМеПѓдї•е∞ЖеЖЕе≠ШдЄ≠зЪДжХ∞жНЃдњЭжМБеЬ®з£БзЫШдЄ≠пЉМйЗНеРѓзЪДжЧґеАЩеПѓдї•еЖНжђ°еК†иљљињЫи°МдљњзФ®гАВ
жКЫеЉАињЩдЇЫпЉМеПѓдї•жЈ±еЕ•еИ∞ Redis еЖЕйГ®жЮДйА†еОїиІВеѓЯжЫіеК†жЬђиі®зЪДеМЇеИЂпЉМзРЖиІ£ Redis зЪДиЃЊиЃ°зРЖењµгАВ
еЬ® Redis дЄ≠пЉМеєґдЄНжШѓжЙАжЬЙзЪДжХ∞жНЃйГљдЄАзЫіе≠ШеВ®еЬ®еЖЕе≠ШдЄ≠зЪДгАВињЩжШѓеТМ Memcached зЫЄжѓФдЄАдЄ™жЬАе§ІзЪДеМЇеИЂгАВ Redis еП™дЉЪзЉУе≠ШжЙАжЬЙ key зЪДдњ°жБѓпЉМе¶ВжЮЬ Redis еПСзО∞еЖЕе≠ШзЪДдљњзФ®йЗПиґЕињЗдЇЖжЯРдЄАдЄ™йШАеАЉпЉМе∞ЖиІ¶еПС swap жУНдљЬпЉМ Redis ж†єжНЃвАЬ swapability = age * log(size_in_memory) вАЭиЃ° зЃЧеЗЇеУ™дЇЫ key еѓєеЇФзЪД value йЬАи¶Б swap еИ∞з£БзЫШпЉМзДґеРОеЖНе∞ЖињЩдЇЫ key еѓєеЇФзЪД value жМБдєЕеМЦеИ∞з£БзЫШдЄ≠пЉМеРМжЧґеЬ®еЖЕе≠ШдЄ≠жЄЕйЩ§гАВињЩзІНзЙєжАІдљњеЊЧ Redis еПѓдї•дњЭжМБиґЕињЗеЕґжЬЇеЩ®жЬђиЇЂеЖЕе≠Ше§Іе∞ПзЪДжХ∞жНЃгАВељУзДґпЉМжЬЇеЩ®жЬђиЇЂзЪДеЖЕе≠ШењЕй°їи¶БиГље§ЯдњЭжМБжЙАжЬЙзЪД key пЉМжѓХзЂЯињЩдЇЫжХ∞жНЃжШѓдЄНдЉЪињЫи°М swap жУНдљЬзЪДгАВеРМжЧґзФ±дЇО Redis е∞ЖеЖЕе≠ШдЄ≠зЪДжХ∞жНЃ swap еИ∞з£БзЫШдЄ≠зЪДжЧґеАЩпЉМжПРдЊЫжЬНеК°зЪДдЄїзЇњз®ЛеТМињЫи°М swapжУНдљЬзЪДе≠РзЇњз®ЛдЉЪеЕ±дЇЂињЩйГ®еИЖеЖЕе≠ШпЉМжЙАдї•е¶ВжЮЬжЫіжЦ∞йЬАи¶Б swap зЪДжХ∞жНЃпЉМ Redis е∞ЖйШїе°ЮињЩдЄ™ жУНдљЬпЉМзЫіеИ∞е≠РзЇњз®ЛеЃМжИР swap жУНдљЬеРОжЙНеПѓдї•ињЫи°МдњЃжФєгАВ
дљњзФ® Redis зЙєжЬЙеЖЕе≠Шж®°еЮЛеЙНеРОзЪДжГЕеЖµеѓєжѓФпЉЪ
VM off: 300k keys, 4096 bytes values: 1.3G used
VM on: 300k keys, 4096 bytes values: 73M used
VM off: 1 million keys, 256 bytes values: 430.12M used
VM on: 1 million keys, 256 bytes values: 160.09M used
VM on: 1 million keys, values as large as you want, still: 160.09M used
ељУдїО Redis дЄ≠иѓїеПЦжХ∞жНЃзЪДжЧґеАЩпЉМе¶ВжЮЬиѓїеПЦзЪД key еѓєеЇФзЪД value дЄНеЬ®еЖЕе≠ШдЄ≠пЉМйВ£дєИ Redis е∞±йЬАи¶БдїО swap жЦЗдїґдЄ≠еК†иљљзЫЄеЇФжХ∞жНЃпЉМзДґеРОеЖНињФеЫЮзїЩиѓЈж±ВжЦєгАВињЩйЗМе∞±е≠ШеЬ®дЄАдЄ™ I/O зЇњз®Л汆зЪДйЧЃйҐШгАВеЬ®йїШиЃ§зЪДжГЕеЖµдЄЛпЉМ Redis дЉЪеЗЇзО∞йШїе°ЮпЉМеН≥еЃМжИРжЙАжЬЙзЪД swap жЦЗдїґеК†иљљеРОжЙНдЉЪеУНеЇФгАВињЩзІНз≠ЦзХ•еЬ®еЃҐжИЈзЂѓзЪДжХ∞йЗПиЊГе∞ПпЉМињЫи°МжЙєйЗПжУНдљЬзЪДжЧґеАЩжѓФиЊГеРИйАВгАВдљЖжШѓе¶ВжЮЬе∞Ж Redis еЇФзФ®еЬ®дЄАдЄ™е§ІеЮЛзЪДзљСзЂЩеЇФзФ®з®ЛеЇПдЄ≠пЉМињЩжШЊзДґжШѓжЧ†ж≥Хжї°иґ≥е§ІеєґеПСзЪДжГЕеЖµзЪДгАВжЙАдї• Redis еЕБиЃЄжИСдїђиЃЊзљЃ I/O зЇњз®Л汆зЪДе§Іе∞ПпЉМеѓєйЬАи¶БдїО swap жЦЗдїґдЄ≠еК†иљљзЫЄеЇФжХ∞жНЃзЪДиѓїеПЦиѓЈж±ВињЫи°МеєґеПСжУНдљЬпЉМеЗПе∞СйШїе°ЮзЪДжЧґйЧігАВ
е¶ВжЮЬеЄМжЬЫеЬ®жµЈйЗПжХ∞жНЃзЪДзОѓеҐГдЄ≠дљњзФ®е•љ Redis пЉМжИСзЫЄдњ°зРЖиІ£ Redis зЪДеЖЕе≠ШиЃЊиЃ°еТМйШїе°ЮзЪДжГЕеЖµжШѓдЄНеПѓзЉЇе∞СзЪДгАВ
==================================================
и°•еЕЕзЪДзЯ•иѓЖзВє
Memcached еТМ Redis зЪДжѓФиЊГ
1. зљСзїЬ IO ж®°еЮЛ
Memcached жШѓе§ЪзЇњз®ЛпЉМйЭЮйШїе°Ю IO е§НзФ®зЪДзљСзїЬж®°еЮЛпЉМеИЖдЄЇзЫСеРђдЄїзЇњз®ЛеТМ worker е≠РзЇњз®ЛпЉМзЫСеРђзЇњз®ЛзЫСеРђзљСзїЬињЮжО•пЉМжО•еПЧиѓЈж±ВеРОпЉМе∞ЖињЮжО•жППињ∞е≠Ч pipe дЉ†йАТзїЩ worker зЇњз®ЛпЉМињЫи°МиѓїеЖЩ IO пЉМзљСзїЬе±ВдљњзФ® libevent е∞Би£ЕзЪДдЇЛдїґеЇУгАВе§ЪзЇњз®Лж®°еЮЛеПѓдї•еПСжМ•е§Ъж†ЄдљЬзФ®пЉМдљЖжШѓеЉХеЕ•дЇЖ cache coherency еТМйФБзЪДйЧЃйҐШгАВжѓФе¶ВпЉМ Memcached жЬАеЄЄзФ®зЪД stats еСљдї§пЉМеЃЮйЩЕдЄК Memcached зЪДжЙАжЬЙжУНдљЬйГљи¶БеѓєињЩдЄ™еЕ®е±АеПШйЗПеК†йФБпЉМињЫи°МиЃ°жХ∞з≠ЙеЈ•дљЬпЉМеЄ¶жЭ•дЇЖжАІиГљжНЯиАЧгАВ
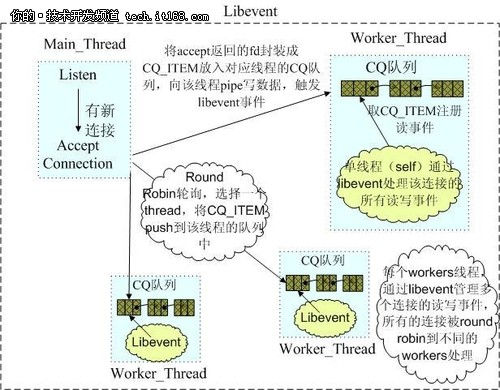
Redis дљњзФ®еНХзЇњз®ЛзЪД IO е§НзФ®ж®°еЮЛпЉМиЗ™еЈ±е∞Би£ЕдЇЖдЄАдЄ™зЃАеНХзЪД AeEvent дЇЛдїґе§ДзРЖж°ЖжЮґпЉМдЄїи¶БеЃЮзО∞дЇЖ epoll гАБ kqueue еТМ select пЉМеѓєдЇОеНХзЇѓеП™жЬЙ IO жУНдљЬзЪДиѓЈж±ВжЭ•иѓіпЉМеНХзЇњз®ЛеПѓдї•е∞ЖйАЯеЇ¶дЉШеКњеПСжМ•еИ∞жЬАе§ІпЉМдљЖжШѓ Redis дєЯжПРдЊЫдЇЖдЄАдЇЫзЃАеНХзЪДиЃ°зЃЧеКЯиГљпЉМжѓФе¶ВжОТеЇПгАБиБЪеРИз≠ЙпЉМеѓєдЇОињЩдЇЫжУНдљЬпЉМеНХзЇњз®Лж®°еЮЛеЃЮйЩЕдЉЪдЄ•йЗНељ±еУНжХідљУеРЮеРРйЗПпЉМ CPU иЃ°зЃЧињЗз®ЛдЄ≠пЉМжХідЄ™ IO и∞ГеЇ¶йГљж؃襀йШїе°ЮдљПзЪДгАВ
2.еЖЕе≠ШзЃ°зРЖжЦєйЭҐ
Memcached дљњзФ®йҐДеИЖйЕНзЪДеЖЕе≠Ш汆зЪДжЦєеЉПпЉМдљњзФ® slab еТМе§Іе∞ПдЄНеРМзЪД chunk жЭ•зЃ°зРЖеЖЕе≠ШгАВ Item ж†єжНЃе§Іе∞ПйАЙжЛ©еРИйАВзЪД chunk е≠ШеВ®пЉМеЖЕе≠Ш汆зЪДжЦєеЉПеПѓдї•зЬБеОїзФ≥иѓЈ/йЗКжФЊеЖЕе≠ШзЪДеЉАйФАпЉМеєґдЄФиГљеЗПе∞ПеЖЕе≠ШзҐОзЙЗдЇІзФЯпЉМдљЖињЩзІНжЦєеЉПдєЯдЉЪеЄ¶жЭ•дЄАеЃЪз®ЛеЇ¶дЄКзЪДз©ЇйЧіжµ™иієпЉМеєґдЄФеЬ®еЖЕе≠ШдїНзДґжЬЙеЊИе§Із©ЇйЧіжЧґпЉМжЦ∞зЪДжХ∞жНЃдєЯеПѓиГљдЉЪ襀еЙФйЩ§пЉМеОЯеЫ†еПѓдї•еПВиАГ Timyang зЪДжЦЗзЂ†пЉЪ http://timyang.net/data/Memcached-lru-evictions/
Redis дљњзФ®зО∞еЬЇзФ≥иѓЈеЖЕе≠ШзЪДжЦєеЉПжЭ•е≠ШеВ®жХ∞жНЃпЉМеєґдЄФеЊИе∞СдљњзФ® free-list з≠ЙжЦєеЉПжЭ•дЉШеМЦеЖЕе≠ШеИЖйЕНпЉМдЉЪеЬ®дЄАеЃЪз®ЛеЇ¶дЄКе≠ШеЬ®еЖЕе≠ШзҐОзЙЗгАВ RedisиЈЯжНЃе≠ШеВ®еСљдї§еПВжХ∞пЉМдЉЪжККеЄ¶ињЗжЬЯжЧґйЧізЪДжХ∞жНЃеНХзЛђе≠ШжФЊеЬ®дЄАиµЈпЉМеєґжККеЃГдїђзІ∞дЄЇдЄіжЧґжХ∞жНЃпЉМйЭЮдЄіжЧґжХ∞жНЃжШѓж∞ЄињЬдЄНдЉЪ襀еЙФйЩ§зЪДпЉМеН≥дЊњзЙ©зРЖеЖЕе≠ШдЄНе§ЯпЉМеѓЉиЗі swap дєЯдЄНдЉЪеЙФйЩ§дїїдљХйЭЮдЄіжЧґжХ∞жНЃпЉИдљЖдЉЪе∞ЭиѓХеЙФйЩ§йГ®еИЖдЄіжЧґжХ∞жНЃпЉЙпЉМињЩзВєдЄК Redis жЫійАВеРИдљЬдЄЇе≠ШеВ®иАМдЄНжШѓ cache гАВ
3.жХ∞жНЃдЄАиЗіжАІйЧЃйҐШ
Memcached жПРдЊЫдЇЖ cas еСљдї§пЉМеПѓдї•дњЭиѓБе§ЪдЄ™еєґеПСиЃњйЧЃжУНдљЬеРМдЄАдїљжХ∞жНЃзЪДдЄАиЗіжАІйЧЃйҐШгАВ Redis ж≤°жЬЙжПРдЊЫ cas еСљдї§пЉМеєґдЄНиГљдњЭиѓБињЩзВєпЉМдЄНињЗ Redis жПРдЊЫдЇЖдЇЛеК°зЪДеКЯиГљпЉМеПѓдї•дњЭиѓБдЄАдЄ≤ еСљдї§зЪДеОЯе≠РжАІпЉМдЄ≠йЧідЄНдЉЪ襀俿дљХжУНдљЬжЙУжЦ≠гАВ
4. е≠ШеВ®жЦєеЉПеПКеЕґеЃГжЦєйЭҐ
Memcached еЯЇжЬђеП™жФѓжМБзЃАеНХзЪД key-value е≠ШеВ®пЉМдЄНжФѓжМБжЮЪдЄЊпЉМдЄНжФѓжМБжМБдєЕеМЦеТМе§НеИґз≠ЙеКЯиГљгАВ Redis йЩ§дЇЖжФѓжМБ key/value е§ЦпЉМињШжФѓжМБ list пЉМ set пЉМ sorted set пЉМ hash з≠ЙдЉЧе§ЪжХ∞жНЃзїУжЮДпЉМжПРдЊЫдЇЖ KEYS ињЫи°МжЮЪдЄЊжУНдљЬпЉМдљЖдЄНиГљеЬ®зЇњдЄКдљњзФ®пЉМе¶ВжЮЬйЬАи¶БжЮЪдЄЊзЇњдЄКжХ∞жНЃпЉМ Redis жПРдЊЫдЇЖеЈ•еЕЈеПѓдї•зЫіжО•жЙЂжППеЕґ dump жЦЗдїґпЉМжЮЪдЄЊеЗЇжЙАжЬЙжХ∞жНЃгАВ Redis ињШеРМжЧґжПРдЊЫдЇЖжМБдєЕеМЦеТМе§НеИґз≠ЙеКЯиГљгАВ
5.еЕ≥дЇОдЄНеРМиѓ≠и®АзЪДеЃҐжИЈзЂѓжФѓжМБ
еЬ®дЄНеРМиѓ≠и®АзЪДеЃҐжИЈзЂѓжЦєйЭҐпЉМ Memcached еТМ Redis йГљжЬЙдЄ∞еѓМзЪДзђђдЄЙжЦєеЃҐжИЈзЂѓеПѓдЊЫйАЙжЛ©пЉМдЄНињЗеЫ†дЄЇ Memcached еПСе±ХзЪДжЧґйЧіжЫідєЕдЄАдЇЫпЉМзЫЃеЙНзЬЛеЬ®еЃҐжИЈзЂѓжФѓжМБжЦєйЭҐпЉМ Memcached зЪДеЊИе§ЪеЃҐжИЈзЂѓжЫіеК†жИРзЖЯз®≥еЃЪпЉМиАМ Redis зФ±дЇОеЕґеНПиЃЃжЬђиЇЂе∞±жѓФ Memcached е§НжЭВпЉМеК†дЄКдљЬиАЕдЄНжЦ≠еҐЮеК†жЦ∞зЪДеКЯиГљз≠ЙпЉМеѓєеЇФзђђдЄЙжЦєеЃҐжИЈзЂѓиЈЯињЫйАЯеЇ¶еПѓиГљдЉЪ赴дЄНдЄКпЉМжЬЙжЧґеПѓиГљйЬАи¶БиЗ™еЈ±еЬ®зђђдЄЙжЦєеЃҐжИЈзЂѓеЯЇз°АдЄКеБЪдЇЫдњЃжФєжЙНиГљжЫіе•љзЪДдљњзФ®гАВ
ж†єжНЃдї•дЄКжѓФиЊГдЄНйЪЊзЬЛеЗЇпЉМељУжИСдїђдЄНеЄМжЬЫжХ∞ж́襀誥еЗЇпЉМжИЦиАЕйЬАи¶БйЩ§ key/value дєЛе§ЦзЪДжЫіе§ЪжХ∞жНЃз±їеЮЛжЧґпЉМжИЦиАЕйЬАи¶БиРљеЬ∞еКЯиГљжЧґпЉМдљњзФ® Redis жѓФдљњзФ® Memcached жЫіеРИйАВгАВ
еЕ≥дЇО Redis зЪДдЄАдЇЫеС®иЊєеКЯиГљ
Redis йЩ§дЇЖдљЬдЄЇе≠ШеВ®дєЛе§ЦињШжПРдЊЫдЇЖдЄАдЇЫеЕґеЃГжЦєйЭҐзЪДеКЯиГљпЉМжѓФе¶ВиБЪеРИиЃ°зЃЧгАБ pubsub гАБ scripting з≠ЙпЉМеѓєдЇОж≠§з±їеКЯиГљйЬАи¶БдЇЖиІ£еЕґеЃЮзО∞еОЯзРЖпЉМжЄЕж•ЪеЬ∞дЇЖиІ£еИ∞еЃГзЪДе±АйЩРжАІеРОпЉМжЙНиГљж≠£з°ЃзЪДдљњзФ®гАВжѓФе¶В pubsub еКЯиГљпЉМињЩдЄ™еЃЮйЩЕжШѓж≤°жЬЙдїїдљХжМБдєЕеМЦжФѓжМБзЪДпЉМжґИиієжЦєињЮжО•йЧ™жЦ≠жИЦйЗНињЮдєЛеРОињЗжЭ•зЪДжґИжБѓжШѓдЉЪеЕ®йî䪥姱зЪДпЉМеПИжѓФе¶ВиБЪеРИиЃ°зЃЧеТМ scripting з≠ЙеКЯиГљеПЧ Redis еНХзЇњз®Лж®°еЮЛжЙАйЩРпЉМжШѓдЄНеПѓиГљиЊЊеИ∞еЊИйЂШзЪДеРЮеРРйЗПзЪДпЉМйЬАи¶Би∞®жЕОдљњзФ®гАВ
жАїзЪДжЭ•иѓі Redis дљЬиАЕжШѓдЄАдљНйЭЮеЄЄеЛ§е•ЛзЪДеЉАеПСиАЕпЉМеПѓдї•зїПеЄЄзЬЛеИ∞дљЬиАЕеЬ®е∞ЭиѓХзЭАеРДзІНдЄНеРМзЪДжЦ∞й≤ЬжГ≥ж≥ХеТМжАЭиЈѓпЉМйТИеѓєињЩдЇЫжЦєйЭҐзЪДеКЯиГље∞±и¶Бж±ВжИСдїђйЬАи¶БжЈ±еЕ•дЇЖиІ£еРОеЖНдљњзФ®гАВ
жАїзїУпЉЪ
1. Redis дљњзФ®жЬАдљ≥жЦєеЉПжШѓеЕ®йГ®жХ∞жНЃ in-memory гАВ
2. Redis жЫіе§ЪеЬЇжЩѓжШѓдљЬдЄЇ Memcached зЪДжЫњдї£иАЕжЭ•дљњзФ®гАВ
3. ељУйЬАи¶БйЩ§ key/value дєЛе§ЦзЪДжЫіе§ЪжХ∞жНЃз±їеЮЛжФѓжМБжЧґпЉМдљњзФ® Redis жЫіеРИйАВгАВ
4. ељУе≠ШеВ®зЪДжХ∞жНЃдЄНиÚ襀еЙФйЩ§жЧґпЉМдљњзФ® Redis жЫіеРИйАВгАВ
Redis дЄО Memcached зЪДеМЇеИЂ
дЉ†зїЯ MySQL + Memcached жЮґжЮДйБЗеИ∞зЪДйЧЃйҐШ
еЃЮйЩЕдЄК MySQL жШѓйАВеРИињЫи°МжµЈйЗПжХ∞жНЃе≠ШеВ®зЪДпЉМйАЪињЗ Memcached е∞ЖзГ≠зВєжХ∞жНЃеК†иљљеИ∞ cache пЉМеК†йАЯиЃњйЧЃпЉМеЊИе§ЪеЕђеПЄйГљжЫЊзїПдљњзФ®ињЗињЩж†ЈзЪДжЮґжЮДпЉМдљЖйЪПзЭАдЄЪеК°жХ∞жНЃйЗПзЪДдЄНжЦ≠еҐЮеК†пЉМеТМиЃњйЧЃйЗПзЪДжМБзї≠еҐЮйХњпЉМжИСдїђйБЗеИ∞дЇЖеЊИе§ЪйЧЃйҐШпЉЪ
1. MySQL йЬАи¶БдЄНжЦ≠ињЫи°МжЛЖеЇУжЛЖи°®пЉМ Memcached дєЯйЬАдЄНжЦ≠иЈЯзЭАжЙ©еЃєпЉМжЙ©еЃєеТМзїіжК§еЈ•дљЬеН†жНЃдЇЖе§ІйЗПеЉАеПСжЧґйЧігАВ
2. Memcached дЄО MySQL жХ∞жНЃеЇУжХ∞жНЃдЄАиЗіжАІйЧЃйҐШгАВ
3. Memcached жХ∞жНЃеСљдЄ≠зОЗдљОжИЦеЃХжЬЇпЉМе§ІйЗПиЃњйЧЃзЫіжО•з©њйАПеИ∞ DB пЉМ MySQL жЧ†ж≥ХжФѓжТСгАВ
4. иЈ®жЬЇжИњ cache еРМж≠•йЧЃйҐШгАВ
дЉЧе§Ъ NoSQL зЩЊиК±йљРжФЊпЉМе¶ВдљХйАЙжЛ©
жЬАињСеЗ†еєіпЉМдЄЪзХМдЄНжЦ≠жґМзО∞еЗЇеЊИе§ЪеРДзІНеРДж†ЈзЪД NoSQL дЇІеУБпЉМйВ£дєИе¶ВдљХжЙНиГљж≠£з°ЃеЬ∞дљњзФ®е•љињЩдЇЫдЇІеУБпЉМжЬАе§ІеМЦеЬ∞еПСжМ•еЕґйХње§ДпЉМжШѓжИСдїђйЬАи¶БжЈ±еЕ•з†Фз©ґеТМжАЭиАГзЪДйЧЃйҐШпЉМеЃЮйЩЕељТж†єзїУеЇХжЬАйЗНи¶БзЪДжШѓдЇЖиІ£ињЩдЇЫдЇІеУБзЪДеЃЪдљНпЉМеєґдЄФдЇЖиІ£еИ∞жѓПжђЊдЇІеУБзЪДдЉШзЉЇзВєпЉМеЬ®еЃЮйЩЕеЇФзФ®дЄ≠еБЪеИ∞жЙђйХњйБњзЯ≠пЉМжАїдљУдЄКињЩдЇЫ NoSQL дЄїи¶БзФ®дЇОиІ£еЖ≥дї•дЄЛеЗ†зІНйЧЃйҐШпЉЪ
1. е∞СйЗПжХ∞жНЃе≠ШеВ®пЉМйЂШйАЯиѓїеЖЩиЃњйЧЃгАВж≠§з±їдЇІеУБйАЪињЗжХ∞жНЃеЕ®йГ® in-memory зЪДжЦєеЉПжЭ•дњЭиѓБйЂШйАЯиЃњйЧЃпЉМеРМжЧґжПРдЊЫжХ∞жНЃиРљеЬ∞зЪДеКЯиГљпЉМеЃЮйЩЕдЄКињЩж≠£жШѓ Redis жЬАдЄїи¶БзЪДйАВзФ®еЬЇжЩѓгАВ
2. жµЈйЗПжХ∞жНЃе≠ШеВ®пЉМеИЖеЄГеЉПз≥їзїЯжФѓжМБпЉМжХ∞жНЃдЄАиЗіжАІдњЭиѓБпЉМжЦєдЊњзЪДйЫЖзЊ§иКВзВєжЈїеК†/еИ†йЩ§гАВињЩжЦєйЭҐжЬАеЕЈдї£и°®жАІзЪДжШѓ dynamo еТМ bigtable 2зѓЗиЃЇжЦЗжЙАйШРињ∞зЪДжАЭиЈѓгАВеЙНиАЕжШѓдЄАдЄ™еЃМеЕ®жЧ†дЄ≠ењГзЪДиЃЊиЃ°пЉМиКВзВєдєЛйЧійАЪињЗ gossip жЦєеЉПдЉ†йАТйЫЖзЊ§дњ°жБѓпЉМжХ∞жНЃдњЭиѓБжЬАзїИдЄАиЗіжАІпЉЫеРОиАЕжШѓдЄАдЄ™дЄ≠ењГеМЦзЪДжЦєж°ИиЃЊиЃ°пЉМйАЪињЗз±їдЉЉдЄАдЄ™еИЖеЄГеЉПйФБжЬНеК°жЭ•дњЭиѓБеЉЇдЄАиЗіжАІпЉМжХ∞жНЃеЖЩеЕ•еЕИеЖЩеЖЕе≠ШеТМ redo log пЉМзДґеРОеЃЪжЬЯ compat ељТеєґеИ∞з£БзЫШдЄКпЉМе∞ЖйЪПжЬЇеЖЩдЉШеМЦдЄЇй°ЇеЇПеЖЩпЉМжПРйЂШеЖЩеЕ•жАІиГљгАВ
3. Schema free пЉМ auto-sharding з≠ЙгАВжѓФе¶ВзЫЃеЙНеЄЄиІБзЪДдЄАдЇЫжЦЗж°£жХ∞жНЃеЇУйГљжШѓжФѓжМБ schema-free зЪДпЉМзЫіжО•е≠ШеВ® json ж†ЉеЉПзЪДжХ∞жНЃпЉМеєґдЄФжФѓжМБ auto-sharding з≠ЙеКЯиГљпЉМжѓФе¶В mongodb гАВ
йЭҐеѓєињЩдЇЫдЄНеРМз±їеЮЛзЪД NoSQL дЇІеУБ,жИСдїђйЬАи¶Бж†єжНЃжИСдїђзЪДдЄЪеК°еЬЇжЩѓйАЙжЛ©жЬАеРИйАВзЪДдЇІеУБгАВ
Redis йАВзФ®еЬЇжЩѓпЉМе¶ВдљХж≠£з°ЃзЪДдљњзФ®
еЙНйЭҐеЈ≤зїПеИЖжЮРињЗпЉМ Redis жЬАйАВеРИжЙАжЬЙжХ∞жНЃ in-memory зЪДеЬЇжЩѓпЉМиЩљзДґ Redis дєЯжПРдЊЫжМБдєЕеМЦеКЯиГљпЉМдљЖеЃЮйЩЕжЫіе§ЪзЪДжШѓдЄАдЄ™ disk-backed зЪДеКЯиГљпЉМиЈЯдЉ†зїЯжДПдєЙдЄКзЪДжМБдєЕеМЦжЬЙжѓФиЊГе§ІзЪДеЈЃеИЂпЉМйВ£дєИеПѓиГље§ІеЃґе∞±дЉЪжЬЙзЦСйЧЃпЉМдЉЉдєО Redis жЫіеГПдЄАдЄ™еК†еЉЇзЙИзЪД Memcached пЉМйВ£дєИдљХжЧґдљњзФ® Memcached пЉМдљХжЧґдљњзФ® Redis еСҐ?
е¶ВжЮЬзЃАеНХеЬ∞жѓФиЊГ Redis дЄО Memcached зЪДеМЇеИЂпЉМе§Іе§ЪжХ∞йГљдЉЪеЊЧеИ∞дї•дЄЛиІВзВєпЉЪ
1. Redis дЄНдїЕдїЕжФѓжМБзЃАеНХзЪД k/v з±їеЮЛзЪДжХ∞жНЃпЉМеРМжЧґињШжПРдЊЫ list пЉМ set пЉМ sorted set пЉМ hash з≠ЙжХ∞жНЃзїУжЮДзЪДе≠ШеВ®гАВ
2. Redis жФѓжМБжХ∞жНЃзЪДе§ЗдїљпЉМеН≥ master-slave ж®°еЉПзЪДжХ∞жНЃе§ЗдїљгАВ
3. Redis жФѓжМБжХ∞жНЃзЪДжМБдєЕеМЦпЉМеПѓдї•е∞ЖеЖЕе≠ШдЄ≠зЪДжХ∞жНЃдњЭжМБеЬ®з£БзЫШдЄ≠пЉМйЗНеРѓзЪДжЧґеАЩеПѓдї•еЖНжђ°еК†иљљињЫи°МдљњзФ®гАВ
жКЫеЉАињЩдЇЫпЉМеПѓдї•жЈ±еЕ•еИ∞ Redis еЖЕйГ®жЮДйА†еОїиІВеѓЯжЫіеК†жЬђиі®зЪДеМЇеИЂпЉМзРЖиІ£ Redis зЪДиЃЊиЃ°зРЖењµгАВ
еЬ® Redis дЄ≠пЉМеєґдЄНжШѓжЙАжЬЙзЪДжХ∞жНЃйГљдЄАзЫіе≠ШеВ®еЬ®еЖЕе≠ШдЄ≠зЪДгАВињЩжШѓеТМ Memcached зЫЄжѓФдЄАдЄ™жЬАе§ІзЪДеМЇеИЂгАВ Redis еП™дЉЪзЉУе≠ШжЙАжЬЙ key зЪДдњ°жБѓпЉМе¶ВжЮЬ Redis еПСзО∞еЖЕе≠ШзЪДдљњзФ®йЗПиґЕињЗдЇЖжЯРдЄАдЄ™йШАеАЉпЉМе∞ЖиІ¶еПС swap жУНдљЬпЉМ Redis ж†єжНЃвАЬ swapability = age * log(size_in_memory) вАЭиЃ° зЃЧеЗЇеУ™дЇЫ key еѓєеЇФзЪД value йЬАи¶Б swap еИ∞з£БзЫШпЉМзДґеРОеЖНе∞ЖињЩдЇЫ key еѓєеЇФзЪД value жМБдєЕеМЦеИ∞з£БзЫШдЄ≠пЉМеРМжЧґеЬ®еЖЕе≠ШдЄ≠жЄЕйЩ§гАВињЩзІНзЙєжАІдљњеЊЧ Redis еПѓдї•дњЭжМБиґЕињЗеЕґжЬЇеЩ®жЬђиЇЂеЖЕе≠Ше§Іе∞ПзЪДжХ∞жНЃгАВељУзДґпЉМжЬЇеЩ®жЬђиЇЂзЪДеЖЕе≠ШењЕй°їи¶БиГље§ЯдњЭжМБжЙАжЬЙзЪД key пЉМжѓХзЂЯињЩдЇЫжХ∞жНЃжШѓдЄНдЉЪињЫи°М swap жУНдљЬзЪДгАВеРМжЧґзФ±дЇО Redis е∞ЖеЖЕе≠ШдЄ≠зЪДжХ∞жНЃ swap еИ∞з£БзЫШдЄ≠зЪДжЧґеАЩпЉМжПРдЊЫжЬНеК°зЪДдЄїзЇњз®ЛеТМињЫи°М swapжУНдљЬзЪДе≠РзЇњз®ЛдЉЪеЕ±дЇЂињЩйГ®еИЖеЖЕе≠ШпЉМжЙАдї•е¶ВжЮЬжЫіжЦ∞йЬАи¶Б swap зЪДжХ∞жНЃпЉМ Redis е∞ЖйШїе°ЮињЩдЄ™ жУНдљЬпЉМзЫіеИ∞е≠РзЇњз®ЛеЃМжИР swap жУНдљЬеРОжЙНеПѓдї•ињЫи°МдњЃжФєгАВ
дљњзФ® Redis зЙєжЬЙеЖЕе≠Шж®°еЮЛеЙНеРОзЪДжГЕеЖµеѓєжѓФпЉЪ
VM off: 300k keys, 4096 bytes values: 1.3G used
VM on: 300k keys, 4096 bytes values: 73M used
VM off: 1 million keys, 256 bytes values: 430.12M used
VM on: 1 million keys, 256 bytes values: 160.09M used
VM on: 1 million keys, values as large as you want, still: 160.09M used
ељУдїО Redis дЄ≠иѓїеПЦжХ∞жНЃзЪДжЧґеАЩпЉМе¶ВжЮЬиѓїеПЦзЪД key еѓєеЇФзЪД value дЄНеЬ®еЖЕе≠ШдЄ≠пЉМйВ£дєИ Redis е∞±йЬАи¶БдїО swap жЦЗдїґдЄ≠еК†иљљзЫЄеЇФжХ∞жНЃпЉМзДґеРОеЖНињФеЫЮзїЩиѓЈж±ВжЦєгАВињЩйЗМе∞±е≠ШеЬ®дЄАдЄ™ I/O зЇњз®Л汆зЪДйЧЃйҐШгАВеЬ®йїШиЃ§зЪДжГЕеЖµдЄЛпЉМ Redis дЉЪеЗЇзО∞йШїе°ЮпЉМеН≥еЃМжИРжЙАжЬЙзЪД swap жЦЗдїґеК†иљљеРОжЙНдЉЪеУНеЇФгАВињЩзІНз≠ЦзХ•еЬ®еЃҐжИЈзЂѓзЪДжХ∞йЗПиЊГе∞ПпЉМињЫи°МжЙєйЗПжУНдљЬзЪДжЧґеАЩжѓФиЊГеРИйАВгАВдљЖжШѓе¶ВжЮЬе∞Ж Redis еЇФзФ®еЬ®дЄАдЄ™е§ІеЮЛзЪДзљСзЂЩеЇФзФ®з®ЛеЇПдЄ≠пЉМињЩжШЊзДґжШѓжЧ†ж≥Хжї°иґ≥е§ІеєґеПСзЪДжГЕеЖµзЪДгАВжЙАдї• Redis еЕБиЃЄжИСдїђиЃЊзљЃ I/O зЇњз®Л汆зЪДе§Іе∞ПпЉМеѓєйЬАи¶БдїО swap жЦЗдїґдЄ≠еК†иљљзЫЄеЇФжХ∞жНЃзЪДиѓїеПЦиѓЈж±ВињЫи°МеєґеПСжУНдљЬпЉМеЗПе∞СйШїе°ЮзЪДжЧґйЧігАВ
е¶ВжЮЬеЄМжЬЫеЬ®жµЈйЗПжХ∞жНЃзЪДзОѓеҐГдЄ≠дљњзФ®е•љ Redis пЉМжИСзЫЄдњ°зРЖиІ£ Redis зЪДеЖЕе≠ШиЃЊиЃ°еТМйШїе°ЮзЪДжГЕеЖµжШѓдЄНеПѓзЉЇе∞СзЪДгАВ
==================================================
и°•еЕЕзЪДзЯ•иѓЖзВє
Memcached еТМ Redis зЪДжѓФиЊГ
1. зљСзїЬ IO ж®°еЮЛ
Memcached жШѓе§ЪзЇњз®ЛпЉМйЭЮйШїе°Ю IO е§НзФ®зЪДзљСзїЬж®°еЮЛпЉМеИЖдЄЇзЫСеРђдЄїзЇњз®ЛеТМ worker е≠РзЇњз®ЛпЉМзЫСеРђзЇњз®ЛзЫСеРђзљСзїЬињЮжО•пЉМжО•еПЧиѓЈж±ВеРОпЉМе∞ЖињЮжО•жППињ∞е≠Ч pipe дЉ†йАТзїЩ worker зЇњз®ЛпЉМињЫи°МиѓїеЖЩ IO пЉМзљСзїЬе±ВдљњзФ® libevent е∞Би£ЕзЪДдЇЛдїґеЇУгАВе§ЪзЇњз®Лж®°еЮЛеПѓдї•еПСжМ•е§Ъж†ЄдљЬзФ®пЉМдљЖжШѓеЉХеЕ•дЇЖ cache coherency еТМйФБзЪДйЧЃйҐШгАВжѓФе¶ВпЉМ Memcached жЬАеЄЄзФ®зЪД stats еСљдї§пЉМеЃЮйЩЕдЄК Memcached зЪДжЙАжЬЙжУНдљЬйГљи¶БеѓєињЩдЄ™еЕ®е±АеПШйЗПеК†йФБпЉМињЫи°МиЃ°жХ∞з≠ЙеЈ•дљЬпЉМеЄ¶жЭ•дЇЖжАІиГљжНЯиАЧгАВ
Redis дљњзФ®еНХзЇњз®ЛзЪД IO е§НзФ®ж®°еЮЛпЉМиЗ™еЈ±е∞Би£ЕдЇЖдЄАдЄ™зЃАеНХзЪД AeEvent дЇЛдїґе§ДзРЖж°ЖжЮґпЉМдЄїи¶БеЃЮзО∞дЇЖ epoll гАБ kqueue еТМ select пЉМеѓєдЇОеНХзЇѓеП™жЬЙ IO жУНдљЬзЪДиѓЈж±ВжЭ•иѓіпЉМеНХзЇњз®ЛеПѓдї•е∞ЖйАЯеЇ¶дЉШеКњеПСжМ•еИ∞жЬАе§ІпЉМдљЖжШѓ Redis дєЯжПРдЊЫдЇЖдЄАдЇЫзЃАеНХзЪДиЃ°зЃЧеКЯиГљпЉМжѓФе¶ВжОТеЇПгАБиБЪеРИз≠ЙпЉМеѓєдЇОињЩдЇЫжУНдљЬпЉМеНХзЇњз®Лж®°еЮЛеЃЮйЩЕдЉЪдЄ•йЗНељ±еУНжХідљУеРЮеРРйЗПпЉМ CPU иЃ°зЃЧињЗз®ЛдЄ≠пЉМжХідЄ™ IO и∞ГеЇ¶йГљж؃襀йШїе°ЮдљПзЪДгАВ
2.еЖЕе≠ШзЃ°зРЖжЦєйЭҐ
Memcached дљњзФ®йҐДеИЖйЕНзЪДеЖЕе≠Ш汆зЪДжЦєеЉПпЉМдљњзФ® slab еТМе§Іе∞ПдЄНеРМзЪД chunk жЭ•зЃ°зРЖеЖЕе≠ШгАВ Item ж†єжНЃе§Іе∞ПйАЙжЛ©еРИйАВзЪД chunk е≠ШеВ®пЉМеЖЕе≠Ш汆зЪДжЦєеЉПеПѓдї•зЬБеОїзФ≥иѓЈ/йЗКжФЊеЖЕе≠ШзЪДеЉАйФАпЉМеєґдЄФиГљеЗПе∞ПеЖЕе≠ШзҐОзЙЗдЇІзФЯпЉМдљЖињЩзІНжЦєеЉПдєЯдЉЪеЄ¶жЭ•дЄАеЃЪз®ЛеЇ¶дЄКзЪДз©ЇйЧіжµ™иієпЉМеєґдЄФеЬ®еЖЕе≠ШдїНзДґжЬЙеЊИе§Із©ЇйЧіжЧґпЉМжЦ∞зЪДжХ∞жНЃдєЯеПѓиГљдЉЪ襀еЙФйЩ§пЉМеОЯеЫ†еПѓдї•еПВиАГ Timyang зЪДжЦЗзЂ†пЉЪ http://timyang.net/data/Memcached-lru-evictions/
Redis дљњзФ®зО∞еЬЇзФ≥иѓЈеЖЕе≠ШзЪДжЦєеЉПжЭ•е≠ШеВ®жХ∞жНЃпЉМеєґдЄФеЊИе∞СдљњзФ® free-list з≠ЙжЦєеЉПжЭ•дЉШеМЦеЖЕе≠ШеИЖйЕНпЉМдЉЪеЬ®дЄАеЃЪз®ЛеЇ¶дЄКе≠ШеЬ®еЖЕе≠ШзҐОзЙЗгАВ RedisиЈЯжНЃе≠ШеВ®еСљдї§еПВжХ∞пЉМдЉЪжККеЄ¶ињЗжЬЯжЧґйЧізЪДжХ∞жНЃеНХзЛђе≠ШжФЊеЬ®дЄАиµЈпЉМеєґжККеЃГдїђзІ∞дЄЇдЄіжЧґжХ∞жНЃпЉМйЭЮдЄіжЧґжХ∞жНЃжШѓж∞ЄињЬдЄНдЉЪ襀еЙФйЩ§зЪДпЉМеН≥дЊњзЙ©зРЖеЖЕе≠ШдЄНе§ЯпЉМеѓЉиЗі swap дєЯдЄНдЉЪеЙФйЩ§дїїдљХйЭЮдЄіжЧґжХ∞жНЃпЉИдљЖдЉЪе∞ЭиѓХеЙФйЩ§йГ®еИЖдЄіжЧґжХ∞жНЃпЉЙпЉМињЩзВєдЄК Redis жЫійАВеРИдљЬдЄЇе≠ШеВ®иАМдЄНжШѓ cache гАВ
3.жХ∞жНЃдЄАиЗіжАІйЧЃйҐШ
Memcached жПРдЊЫдЇЖ cas еСљдї§пЉМеПѓдї•дњЭиѓБе§ЪдЄ™еєґеПСиЃњйЧЃжУНдљЬеРМдЄАдїљжХ∞жНЃзЪДдЄАиЗіжАІйЧЃйҐШгАВ Redis ж≤°жЬЙжПРдЊЫ cas еСљдї§пЉМеєґдЄНиГљдњЭиѓБињЩзВєпЉМдЄНињЗ Redis жПРдЊЫдЇЖдЇЛеК°зЪДеКЯиГљпЉМеПѓдї•дњЭиѓБдЄАдЄ≤ еСљдї§зЪДеОЯе≠РжАІпЉМдЄ≠йЧідЄНдЉЪ襀俿дљХжУНдљЬжЙУжЦ≠гАВ
4. е≠ШеВ®жЦєеЉПеПКеЕґеЃГжЦєйЭҐ
Memcached еЯЇжЬђеП™жФѓжМБзЃАеНХзЪД key-value е≠ШеВ®пЉМдЄНжФѓжМБжЮЪдЄЊпЉМдЄНжФѓжМБжМБдєЕеМЦеТМе§НеИґз≠ЙеКЯиГљгАВ Redis йЩ§дЇЖжФѓжМБ key/value е§ЦпЉМињШжФѓжМБ list пЉМ set пЉМ sorted set пЉМ hash з≠ЙдЉЧе§ЪжХ∞жНЃзїУжЮДпЉМжПРдЊЫдЇЖ KEYS ињЫи°МжЮЪдЄЊжУНдљЬпЉМдљЖдЄНиГљеЬ®зЇњдЄКдљњзФ®пЉМе¶ВжЮЬйЬАи¶БжЮЪдЄЊзЇњдЄКжХ∞жНЃпЉМ Redis жПРдЊЫдЇЖеЈ•еЕЈеПѓдї•зЫіжО•жЙЂжППеЕґ dump жЦЗдїґпЉМжЮЪдЄЊеЗЇжЙАжЬЙжХ∞жНЃгАВ Redis ињШеРМжЧґжПРдЊЫдЇЖжМБдєЕеМЦеТМе§НеИґз≠ЙеКЯиГљгАВ
5.еЕ≥дЇОдЄНеРМиѓ≠и®АзЪДеЃҐжИЈзЂѓжФѓжМБ
еЬ®дЄНеРМиѓ≠и®АзЪДеЃҐжИЈзЂѓжЦєйЭҐпЉМ Memcached еТМ Redis йГљжЬЙдЄ∞еѓМзЪДзђђдЄЙжЦєеЃҐжИЈзЂѓеПѓдЊЫйАЙжЛ©пЉМдЄНињЗеЫ†дЄЇ Memcached еПСе±ХзЪДжЧґйЧіжЫідєЕдЄАдЇЫпЉМзЫЃеЙНзЬЛеЬ®еЃҐжИЈзЂѓжФѓжМБжЦєйЭҐпЉМ Memcached зЪДеЊИе§ЪеЃҐжИЈзЂѓжЫіеК†жИРзЖЯз®≥еЃЪпЉМиАМ Redis зФ±дЇОеЕґеНПиЃЃжЬђиЇЂе∞±жѓФ Memcached е§НжЭВпЉМеК†дЄКдљЬиАЕдЄНжЦ≠еҐЮеК†жЦ∞зЪДеКЯиГљз≠ЙпЉМеѓєеЇФзђђдЄЙжЦєеЃҐжИЈзЂѓиЈЯињЫйАЯеЇ¶еПѓиГљдЉЪ赴дЄНдЄКпЉМжЬЙжЧґеПѓиГљйЬАи¶БиЗ™еЈ±еЬ®зђђдЄЙжЦєеЃҐжИЈзЂѓеЯЇз°АдЄКеБЪдЇЫдњЃжФєжЙНиГљжЫіе•љзЪДдљњзФ®гАВ
ж†єжНЃдї•дЄКжѓФиЊГдЄНйЪЊзЬЛеЗЇпЉМељУжИСдїђдЄНеЄМжЬЫжХ∞ж́襀誥еЗЇпЉМжИЦиАЕйЬАи¶БйЩ§ key/value дєЛе§ЦзЪДжЫіе§ЪжХ∞жНЃз±їеЮЛжЧґпЉМжИЦиАЕйЬАи¶БиРљеЬ∞еКЯиГљжЧґпЉМдљњзФ® Redis жѓФдљњзФ® Memcached жЫіеРИйАВгАВ
еЕ≥дЇО Redis зЪДдЄАдЇЫеС®иЊєеКЯиГљ
Redis йЩ§дЇЖдљЬдЄЇе≠ШеВ®дєЛе§ЦињШжПРдЊЫдЇЖдЄАдЇЫеЕґеЃГжЦєйЭҐзЪДеКЯиГљпЉМжѓФе¶ВиБЪеРИиЃ°зЃЧгАБ pubsub гАБ scripting з≠ЙпЉМеѓєдЇОж≠§з±їеКЯиГљйЬАи¶БдЇЖиІ£еЕґеЃЮзО∞еОЯзРЖпЉМжЄЕж•ЪеЬ∞дЇЖиІ£еИ∞еЃГзЪДе±АйЩРжАІеРОпЉМжЙНиГљж≠£з°ЃзЪДдљњзФ®гАВжѓФе¶В pubsub еКЯиГљпЉМињЩдЄ™еЃЮйЩЕжШѓж≤°жЬЙдїїдљХжМБдєЕеМЦжФѓжМБзЪДпЉМжґИиієжЦєињЮжО•йЧ™жЦ≠жИЦйЗНињЮдєЛеРОињЗжЭ•зЪДжґИжБѓжШѓдЉЪеЕ®йî䪥姱зЪДпЉМеПИжѓФе¶ВиБЪеРИиЃ°зЃЧеТМ scripting з≠ЙеКЯиГљеПЧ Redis еНХзЇњз®Лж®°еЮЛжЙАйЩРпЉМжШѓдЄНеПѓиГљиЊЊеИ∞еЊИйЂШзЪДеРЮеРРйЗПзЪДпЉМйЬАи¶Би∞®жЕОдљњзФ®гАВ
жАїзЪДжЭ•иѓі Redis дљЬиАЕжШѓдЄАдљНйЭЮеЄЄеЛ§е•ЛзЪДеЉАеПСиАЕпЉМеПѓдї•зїПеЄЄзЬЛеИ∞дљЬиАЕеЬ®е∞ЭиѓХзЭАеРДзІНдЄНеРМзЪДжЦ∞й≤ЬжГ≥ж≥ХеТМжАЭиЈѓпЉМйТИеѓєињЩдЇЫжЦєйЭҐзЪДеКЯиГље∞±и¶Бж±ВжИСдїђйЬАи¶БжЈ±еЕ•дЇЖиІ£еРОеЖНдљњзФ®гАВ
жАїзїУпЉЪ
1. Redis дљњзФ®жЬАдљ≥жЦєеЉПжШѓеЕ®йГ®жХ∞жНЃ in-memory гАВ
2. Redis жЫіе§ЪеЬЇжЩѓжШѓдљЬдЄЇ Memcached зЪДжЫњдї£иАЕжЭ•дљњзФ®гАВ
3. ељУйЬАи¶БйЩ§ key/value дєЛе§ЦзЪДжЫіе§ЪжХ∞жНЃз±їеЮЛжФѓжМБжЧґпЉМдљњзФ® Redis жЫіеРИйАВгАВ
4. ељУе≠ШеВ®зЪДжХ∞жНЃдЄНиÚ襀еЙФйЩ§жЧґпЉМдљњзФ® Redis жЫіеРИйАВгАВ
еИЖдЇЂеИ∞пЉЪ


- 2016-04-22 13:20
- жµПиІИ 786
- иѓДиЃЇ(0)
- еИЖз±ї:еЉАжЇРиљѓдїґ
- жЯ•зЬЛжЫіе§Ъ
еПСи°®иѓДиЃЇ

-
гАРиљђгАСRedis йЫЖзЊ§дєЛиЈѓзФ±
2016-05-28 15:08 1093йЂШжХИињРзїіжЬАдљ≥еЃЮиЈµпЉИ03пЉЙпЉЪRedisйЫЖзЊ§жКАжЬѓеПКCodisеЃЮиЈµ -
гАРиљђгАСRedisзЪДJavaеЃҐжИЈзЂѓJedisзЪДеЕЂзІНи∞ГзФ®жЦєеЉП(дЇЛеК°гАБзЃ°йБУгАБеИЖеЄГеЉП)дїЛзїН
2016-05-28 14:38 594RedisзЪДJavaеЃҐжИЈзЂѓJedisзЪДеЕЂзІНи∞ГзФ®жЦєеЉП(дЇЛеК°гАБзЃ°йБУ ... -
гАРиљђгАСRedis зЃАеНХдљњзФ®
2016-05-09 11:21 440жЬђжЦЗиљђиЗ™еНЪеЃҐеЫ≠з≥їеИЧжЦЗзЂ†гАВ йЂШжАІиГљзљСзЂЩжЮґжЮДиЃЊиЃ°дєЛзЉУе≠ШзѓЗпЉИ1пЉЙ ... -
гАРиљђгАСзРЖиІ£дЇЛеК°вАФвАФеОЯе≠РжАІгАБдЄАиЗіжАІгАБйЪФз¶їжАІеТМжМБдєЕжАІ
2016-05-04 19:48 968еОЯжЦЗеЬ∞еЭАпЉЪhttp://blog.csdn.net/chose ... -
гАРиљђгАСMySQL 糥еЉХеОЯзРЖеПКжЕҐжߕ胥дЉШеМЦ
2016-04-28 18:32 671жЬђжЦЗиљђиЗ™пЉЪ http://www.cnblogs.com/al ... -
еЃЮзО∞еИЖеЄГеЉПйФБзЪДеЗ†зІНжЦєеЉП
2016-04-26 13:18 46541. еЃМеЕ®еЯЇдЇОжХ∞жНЃеЇУ зФ®дєР ... -
Memcached еТМ Redis жАїзїУ
2016-04-22 18:30 626дЄАгАБ Memcached VS Redis и°®йЭҐдЄКзЪДдЄНеРМ 1 ... -
гАРиљђгАСи∞Ии∞И Memcached дЄО Redis
2016-04-22 17:21 604жИ™еПЦжЦЗзЂ†зЪДдЄАе∞ПйГ®еИЖпЉМе ... -
гАРиљђгАСжИСиѓїињЗжЬАе•љзЪД Epoll ж®°еЮЛиЃ≤иІ£
2016-04-21 18:11 2331й¶ЦеЕИжИСдїђжЭ•еЃЪдєЙжµБзЪДж¶Ве ... -
RedisUtil
2015-06-20 23:19 1360package com.jianfeitech.utils ... -
Mysql еИЖеМЇ ------ Innodb и°®еЉХжУО
2015-06-13 01:34 1039еѓєдЇО myisam еЉХжУОзЪДжХ∞жНЃеЇУпЉМеЃГзЪДжЙАжЬЙи°®еЬ®зЙ©зРЖдЄКжШѓеИЖеЉАзЪДгАВ ... -
Mysql иѓїеЖЩеИЖз¶їзЪД Java еЃЮзО∞
2015-06-12 17:06 1133еЕИдЄКдї£з†Б public class DynamicDat ...
зЫЄеЕ≥жО®иНР
redisдЄОmemcachedжѓФиЊГпЉМеЬ®еБЪз≥їзїЯйАЙеЮЛжЧґпЉМеПѓдї•еПВиАГгАВз≥їзїЯеНЗзЇІжЧґпЉМдєЯеПѓдї•еАЯйЙігАВ
иЃ°зЃЧжЬЇеРОзЂѓ-PHPиІЖйҐСжХЩз®Л. Redis01 RedisдЄОMemcachedзЪДеМЇеИЂ.wmv
10.1.1 redisзЫЄжѓФmemcachedжЬЙеУ™дЇЫдЉШеКњпЉЯ
еИЖеЄГеЉПзЉУе≠Ш Redis + Memcached зїПеЕЄйЭҐиѓХйҐШпЉБ
php mysql redis nginx memcached
зЂЮеУБеИЖжЮРдєЛredisеЉЇдЇОmemcached redisдЄїдїОеИЗжНҐ 1.redisжФѓжМБжМБдєЕеМЦ(е≠ШзЫШ),memcacheеП™иГље≠ШеЬ®еЖЕе≠ШдЄ≠ 2.redisзЪДйАЯеЇ¶жѓФmemcachedењЂеЊИе§Ъ.RedisзЫіжО•иЗ™еЈ±жЮДеїЇдЇЖVM жЬЇеИґ пЉМеЫ†дЄЇдЄАиИђзЪДз≥їзїЯи∞ГзФ®з≥їзїЯеЗљжХ∞зЪДиѓЭпЉМдЉЪжµ™иієдЄАеЃЪзЪДжЧґйЧіеОї...
дљњзФ®c#иѓїеПЦmemcachedдЄ≠зЪДжХ∞жНЃпЉМеЖНиљђзІїеИ∞жМЗеЃЪзЪДredisдЄ≠гАВиІ£еЖ≥жѓФе¶ВtokenзЪДдњЭжМБ,иЃ©еЃҐжИЈзЂѓзЩїељХдЄНжХИгАВ
TreeNMSпЉМTreeSoftжХ∞жНЃеЇУзЃ°зРЖз≥їзїЯ for Redis, memcachedпЉМеЕНиієпЉМиґЕе•љзФ®зЪДRedisзЃ°зРЖеПКзЫСжОІеЈ•еЕЈtreeNMS
Zend_Cache Redis Memcached жЙ©е±Х
Memcached vs RedisпЉМжАїзїУзЪДеНБеИЖжЄЕжЩ∞еТМиѓ¶зїЖгАВ
redisпЉЪRedis-x64-3.2.100.msi + Redis-x64-3.2.100.zip + php_redis-4.2.0-7.3-ts-vc15-x64.zip redisеЃЙи£ЕпЉЪ.msiжЦЗдїґжЙУеЉАзЫіжО•еЃЙи£ЕеН≥еПѓпЉМж≥®жДПйАЙжЛ©жЈїеК†pattйАЙй°є memcached: memcached-win64-1.4.4-14 + ...
дєЛеЙНзФ®ињЗredisеТМMongoDBпЉМдљЖйГљжШѓж≤°жЬЙз≥їзїЯзЪДе≠¶дє†пЉМжЦ∞еЕђеПЄзФ®еИ∞memcachedпЉМжЙАдї•еОїдЇЖиІ£дїЦдїђзЪДеМЇеИЂеТМеЇФзФ®еЬЇжЩѓпЉМжЦєдЊњзРЖиІ£гАВ
еИЖеЄГеЉПзЉУе≠Ш Redis + Memcached зїПеЕЄйЭҐиѓХйҐШпЉБ
canal зЪД mysql дЄО redis/memcached/mongodb зЪД nosql жХ∞жНЃеЃЮжЧґеРМж≠•жЦєж°И
дЄїи¶БдїЛзїНдЇЖRedisеТМMemcachedзЪДеМЇеИЂиѓ¶иІ£,жЬђжЦЗдїОеРДжЦєйЭҐжАїзїУдЇЖдЄ§дЄ™жХ∞жНЃеЇУзЪДдЄНеРМдєЛе§Д,йЬАи¶БзЪДжЬЛеПЛеПѓдї•еПВиАГдЄЛ
дЄНеЕЙжЬЙеРЂйЗСйЗПпЉМињШеЊИжЬЙйҐЬеАЉгАВ Redis-vs-Memcached-Infographic-ScaleGrid-Blog
дЇТиБФзљСеИЖеЄГеЉПзЉУе≠ШжКАжЬѓ¬†иѓЊз®ЛдЄїиЃ≤пЉЪ¬†дЇТиБФзљСеЇФзФ®йЂШзЇІжЮґжЮДеЄИ¬†зЩљиіЇзњФжґЙеПКжКАжЬѓпЉЪ¬†RedisгАБSSDBгАБMemcachedиѓЊз®ЛжППињ∞пЉЪ¬†дїЛзїНдЇТиБФзљСеИЖеЄГеЉПжКАжЬѓзЪДйЗНи¶БжАІгАБиГМжЩѓгАБеЇФзФ®иМГеЫіпЉЫзЫЃеЙНдЇТиБФзљСи°МдЄЪдљњзФ®еИЖеЄГ еЉПзЉУе≠ШињЫи°МиЃЊиЃ°зЪДжѓФдЊЛпЉМ...
йЂШзЇІеИЖеЄГеЉПжХ∞жНЃеЇУжХЩз®ЛпЉМnosqlпЉМmongodb,redisгАВйЭЮеЄЄе•љзЪДеИЖеЄГеЉПжХЩз®ЛпЉБ